ㅁ 서브쿼리 종류

ㅁ 서브쿼리는 대부분 단일행 서브쿼리가 많이 사용된다.
ㅁ < 서브쿼리 SUBQUERY >
- 하나의 쿼리문 안에 포함되어있는 또다른 쿼리문
- 메인 쿼리를 위해 보조 역할을 수행
- 서브쿼리가 먼저 실행되고 메인쿼리가 실행된다.
ㅁ 서브쿼리의 종류
- SELECT절 : 스칼라 서브쿼리
- FROM절: 인라인 뷰
- WHERE절 : 단일행, 다중행, 다중열, 다중행다중열 서브쿼리
ㅁ 예제 (노옹철 사원과 같은 부서에 속한 사원들 조회)
SELECT DEPT_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '노옹철'; // D9
SELECT EMP_NAME
FROM EMPLOYEE
WHERE DEPT_CODE = 'D9';
- 이 두 과정을 하나의 쿼리로 축약.
SELECT EMP_NAME
FROM EMPLOYEE
WHERE DEPT_CODE = ( SELECT DEPT_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '노옹철' );
- 서브쿼리가 먼저 수행된다.
ㅇ 변형 (DEPARTMENT 테이블의 직급명도 조회)
(1) 오라클
SELECT EMP_NAME, NVL(DEPT_TITLE, '부서없음')
FROM EMPLOYEE, DEPARTMENT
WHERE SALARY > (SELECT SALARY
FROM EMPLOYEE
WHERE EMP_NAME = '노옹철'
)
AND DEPT_CODE = DEPT_ID(+) ;
- DEPT_CODE가 NULL인 사원들도 포함하고 싶다면 내부조인이 아닌 외부조인을 해야 함.
(2) ANSI
SELECT EMP_NAME, NVL(DEPT_TITLE, '부서없음')
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON DEPT_CODE = DEPT_ID
WHERE SALARY > (SELECT SALARY
FROM EMPLOYEE
WHERE EMP_NAME = '노옹철' );
ㅁ < 단일행 서브쿼리 SINGLE ROW SUBQUERY >
- 이걸 많이 씀.
- 서브쿼리의 결과값이 오로지 1개인 경우. 한 열, 한 행인 경우.
- 일반 비교연산자 사용 가능(결과값이 1개이기 때문에)
=, !=, ^=, <>, <, <=, >, >=
ㅁ 보통 서브쿼리로 푸는 문제들은 조인으로 풀 수도 있다.
뭐가 더 효율적인지는 그때 그때 다름.
ㅁ 예제 (사수가 선동일인 사원의 사번, 이름, 사수사번)
- 이건 조인이 필수가 아닌 이유가, EMPLOYEE 테이블에 있는 컬럼명만 조회하기 때문.
(1) SELF JOIN 방식
SELECT E1.EMP_ID, E1.EMP_NAME, E1.MANAGER_ID
FROM EMPLOYEE E1, EMPLOYEE E2
WHERE E1.MANAGER_ID = E2.EMP_ID
AND E2.EMP_NAME = '선동일';
(2) 서브쿼리 방식
SELECT EMP_ID, EMP_NAME, MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID = (SELECT EMP_ID
FROM EMPLOYEE
WHERE EMP_NAME = '선동일');
ㅁ 예제 (전지연 사원과 같은 부서원의 사원명과 부서명)
- 이건 조인이 필수인 이유가, DEPARTMENT 테이블의 DEPT_TITLE을 조회해서.
(1) 오라클
SELECT EMP_NAME, DEPT_TITLE
FROM EMPLOYEE, DEPARTMENT
WHERE DEPT_CODE = DEPT_ID
AND DEPT_CODE = (SELECT DEPT_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '전지연')
AND EMP_NAME <> '전지연';
(2) ANSI 방식
SELECT EMP_NAME, DEPT_TITLE
FROM EMPLOYEE
JOIN DEPARTMENT ON DEPT_CODE = DEPT_ID
WHERE DEPT_CODE = (SELECT DEPT_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '전지연')
AND EMP_NAME <> '전지연';
ㅁ 예제 (부서별 급여합이 가장 큰 부서의 부서코드)
- 먼저 두 개의 쿼리를 차례로 작성해 본다.
SELECT MAX( SUM(SALARY ) )
FROM EMPLOYEE
GROUP BY DEPT_CODE; // 17660000
SELECT DEPT_CODE
FROM EMPLOYEE
GROUP BY DEPT_CODE
HAVING SUM(SALARY) = 17660000;
- 서브쿼리 적용
SELECT DEPT_CODE
FROM EMPLOYEE
GROUP BY DEPT_CODE
HAVING SUM(SALARY) = ( SELECT MAX( SUM(SALARY ) )
FROM EMPLOYEE
GROUP BY DEPT_CODE);
- MAX(서브쿼리) 이건 안 됨. 집계함수는 쿼리 안에 있어야 함.
집계함수는 GROUP BY 뒤인 HAVING, SELECT, ORDER BY 에 온다.
ㅁ < 다중행 서브쿼리 MULTI ROW SUBQUERY >
- 서브쿼리의 결과값이 여러 행인 경우
- 서브쿼리를 가지고 일반 비교연산자와 함께 사용할 수 없다.
- 앞에 비교대상 컬럼이 온다. 다중행이니까.
- IN, ANY/SOME, ALL
비교대상 컬럼 IN (서브쿼리) : 여러개의 결과값 중에서 한개라도 일치하는 값이 있다면 조회 . (= '= ANY')
비교대상 컬럼 > ANY (서브쿼리) : 비교대상 컬럼과 비교연산을 해서, 서브쿼리의 여러개의 결과값들보다 한번이라도 크면 조회.
비교대상 컬럼 < ANY (서브쿼리) : 비교대상 컬럼과 비교연산을 해서, 서브쿼리의 여러개의 결과값들보다 한번이라도 작으면 조회.
비교대상 컬럼 > ALL (서브쿼리) : 비교대상 컬럼과 비교연산을 해서, 서브쿼리의 모든 결과값들보다 큰 경우를 조회.
비교대상 컬럼 < ALL (서브쿼리) : 비교대상 컬럼과 비교연산을 해서, 서브쿼리의 모든 결과값들보다 큰 경우를 조회.
ㅁ 예제 (유재식 또는 윤은해 사원과 같은 직급인 사원 조회)
- 두 번으로 나눔.
SELECT JOB_CODE
FROM EMPLOYEE
WHERE EMP_NAME IN ('유재식', '윤은해'); // J3, J7
SELECT *
FROM EMPLOYEE
WHERE JOB_CODE IN ('J3', 'J7');
- 서브쿼리 적용
SELECT *
FROM EMPLOYEE
WHERE JOB_CODE IN ( SELECT JOB_CODE
FROM EMPLOYEE
WHERE EMP_NAME IN ('유재식', '윤은해') );
SELECT *
FROM EMPLOYEE
WHERE JOB_CODE = ANY ( SELECT JOB_CODE
FROM EMPLOYEE
WHERE EMP_NAME IN ('유재식', '윤은해') );
ㅁ 예제 (사수가 D9부서인 사원의 사번, 이름, 사수사번 조회)
SELECT EMP_ID, EMP_NAME, MANAGER_ID
FROM EMPLOYEE
WHERE MANAGER_ID IN (SELECT EMP_ID
FROM EMPLOYEE
WHERE DEPT_CODE = 'D9')
;
ㅁ 예제 (대리직급이지만 과장 직급 급여들 중 최소급여보다 더 많이 받는 직원의 사번, 이름, 직급, 급여 조회)
- 사원 < 대리 < 과장 < 차장 < 부장
SELECT EMP_ID, EMP_NAME, EMPLOYEE.JOB_CODE, SALARY
FROM EMPLOYEE, JOB
WHERE EMPLOYEE.JOB_CODE = JOB.JOB_CODE
AND JOB_NAME = '대리'
AND SALARY > ANY(SELECT SALARY
FROM EMPLOYEE
WHERE JOB_NAME = '과장');
- 오류는 안나지만 아무것도 결과가 안 나옴. 이유는 서브쿼리에서, EMPLOYEE 테이블에 JOB_NAME이 없기 때문.
- 이걸 두 단계로 나누면, 각각 다 조인이 필요한 쿼리이다.
SELECT EMP_ID, EMP_NAME, EMPLOYEE.JOB_CODE, SALARY
FROM EMPLOYEE, JOB
WHERE EMPLOYEE.JOB_CODE = JOB.JOB_CODE
AND JOB_NAME = '대리'
AND SALARY > ANY(SELECT SALARY
FROM EMPLOYEE, JOB
WHERE EMPLOYEE.JOB_CODE = JOB.JOB_CODE
AND JOB_NAME = '과장');
ㅁ 예제 (차장이지만 모든 부장들의 급여보다 더 많이 받는 직원의 사번, 이름, 직급, 급여 조회 )
SELECT EMP_ID, EMP_NAME, EMPLOYEE.JOB_CODE, SALARY
FROM EMPLOYEE, JOB
WHERE EMPLOYEE.JOB_CODE = JOB.JOB_CODE
AND JOB_NAME = '차장'
AND SALARY > ALL (SELECT SALARY
FROM EMPLOYEE, JOB
WHERE EMPLOYEE.JOB_CODE = JOB.JOB_CODE
AND JOB_NAME = '부장');
ㅁ < 다중열 서브쿼리 >
- 서브쿼리의 결과값이 한 행이지만, 나열된 컬럼 수가 여러개일 경우 (컬럼 수는 같아야 함!)
- 여러 컬럼과 동시에 비교할 수 있음.
- 일반 비교연산자 사용 가능.
- 다중열 서브쿼리는 단일행 서브쿼리로도 해결 가능함.
ㅁ 예제 (하이유 사원과 같은 부서, 같은 직급인 사원의 사원명, 부서코드, 직급코드, 입사일)
(1) 단일행 서브쿼리 방식
SELECT EMP_NAME, DEPT_CODE, JOB_CODE, HIRE_DATE
FROM EMPLOYEE
WHERE DEPT_CODE = ( SELECT DEPT_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '하이유') // D5. 결과값이 하나라는 것은 단일행 서브쿼리인 것이다.
AND JOB_CODE = ( SELECT JOB_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '하이유'); // J5. 결과값이 하나라는 것은 단일행 서브쿼리인 것이다.
(2) 단일행 다중열 서브쿼리 방식
SELECT EMP_NAME, DEPT_CODE, JOB_CODE, HIRE_DATE
FROM EMPLOYEE
WHERE ( DEPT_CODE, JOB_CODE ) = ( SELECT DEPT_CODE, JOB_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '하이유') ;
SELECT EMP_NAME, DEPT_CODE, JOB_CODE, HIRE_DATE
FROM EMPLOYEE
WHERE ( DEPT_CODE, JOB_CODE ) IN ( SELECT DEPT_CODE, JOB_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '하이유') ;
ㅁ < 다중행 다중열 서브쿼리 >
- 서브쿼리의 결과값이 여러행 여러열일 경우
- 여러 컬럼과 동시에 비교 가능, 단 일반 비교연산자 사용 불가
ㅁ 예제 (각 직급별 최소급여를 받는 사원의 사번, 사원명, 직급코드, 급여 조회)
SELECT EMP_ID, EMP_NAME, JOB_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY IN (SELECT MIN(SALARY)
FROM EMPLOYEE
GROUP BY JOB_CODE);
- 이렇게 한 컬럼만 비교하면 안 됨.
다른 그룹의 최소급여랑 이 그룹의 최소급여랑 우연히 같으면 연결되어서 더 나옴.
SELECT EMP_ID, EMP_NAME, JOB_CODE, SALARY
FROM EMPLOYEE
WHERE (SALARY,JOB_CODE) IN (SELECT MIN(SALARY),JOB_CODE
FROM EMPLOYEE
GROUP BY JOB_CODE);
ㅁ 예제 (각 부서별 최고급여를 받는 사원의 사번, 사원명, 부서코드, 급여 조회)
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE (SALARY, DEPT_CODE) IN (SELECT MAX(SALARY),DEPT_CODE
FROM EMPLOYEE
GROUP BY DEPT_CODE);
- DEPT_CODE가 NULL인 사원들은 안 나옴.
나오게 하고 싶으면 DEPT_CODE 대신 NVL(DEPT_CODE, '없음') 쓰면 됨. 3곳 다.








ㅁ <인라인 뷰 INLINE-VIEW >
- FROM절에 작성된 서브쿼리
- 서브쿼리 수행 결과를 마치 하나의 테이블(임시테이블) 처럼 사용 가능
- 주로 TOP-N 분석시 많이 사용됨. TOP-N 분석은 가장 높은 데이터 일부만을 조회(급여별 최상위 몇 명)하겠다.
ㅁ 예제 (사번, 이름, 보너스포함연봉, 부서코드 조회)(단, 보너스 포함 연봉이 3000만원 이상인 사람만 조회)
(1) 일반
SELECT EMP_ID, EMP_NAME, (SALARY * (1+NVL(BONUS, 0)))*12 AS "연봉", DEPT_CODE
FROM EMPLOYEE
WHERE (SALARY * (1+NVL(BONUS, 0)))*12 >= 30000000
ORDER BY 3 DESC;
- 이렇게 하면 WHERE에 별칭을 못 씀.
(2) 인라인 뷰
SELECT *
FROM (SELECT EMP_ID, EMP_NAME, (SALARY * (1+NVL(BONUS, 0)))*12 AS "연봉", DEPT_CODE
FROM EMPLOYEE)
WHERE 연봉 >= 30000000
ORDER BY 3 DESC;
ㅁ 예제 (전 사원 중 급여가 가장 높은 상위 5명만 조회)
SELECT EMP_NAME, SALARY
FROM EMPLOYEE
ORDER BY 2 DESC;
- 지금이야 SALARY가 3700000 이상인 사원만 조회하면 상위 5명이지만, 데이터 자체가 나중에 달라질 수도 있다.
- ROWNUM이라는 오라클에서 제공하는 컬럼 사용.
조회된 순서대로 1부터 순번을 부여해준다.
SELECT EMP_NAME, SALARY, ROWNUM
FROM EMPLOYEE
ORDER BY 2 DESC;
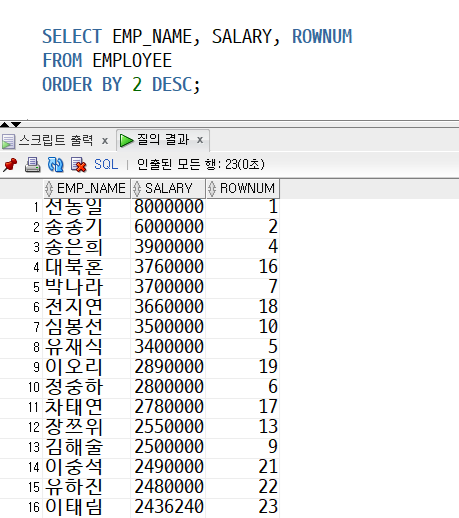
- 근데 내가 원하는 결과가 안 나옴.
왜냐하면 ORDER BY가 SELECT절보다 실행순서가 뒤기 때문.
SELECT EMP_NAME, SALARY, ROWNUM
FROM EMPLOYEE
WHERE ROWNUM <= 5
ORDER BY 2 DESC;
- 그래서 상위 5명을 조회하는 것도 원하는 결과가 안 나옴.

- SELECT 절 전에 ORDER BY가 되어야 내가 원하는 결과가 나온다.
ㅇ 아래는 오류 발생
SELECT *, ROWNUM
FROM (SELECT EMP_NAME, SALARY, ROWNUM
FROM EMPLOYEE
ORDER BY 2 DESC)
WHERE ROWNUM <= 5;

- 이렇게 인라인 뷰에 별칭 부여하면 서브쿼리 안의 ROWNUM(ROWNUM)도 볼 수 있다.
ㅁ 예제 (가장 최근에 입사한 사원 3명의 사원명, 급여, 입사일 조회)

ㅁ 예제 (각 부서별 평균급여가 높은 3개의 부서들의 부서코드, 평균급여 조회)
SELECT *
FROM (SELECT DEPT_CODE, TRUNC(AVG(SALARY))
FROM EMPLOYEE
GROUP BY DEPT_CODE
ORDER BY 2 DESC)
WHERE ROWNUM <= 3;
- 애초에 인라인 뷰에서 가져온 게 2개 칼럼 밖에 없으니 바깥에 *만 써도 됨.
- 인라인 뷰 끝난 다음에 GROUP BY와 HAVING을 또 하는게 아니고, WHERE로 ROWNUM 쓴다.
ㅁ ROWNUM 단점
- 1부터 시작되는 범위만 조회 가능함.
WHERE ROWNUM BETWEEN 1 AND 3은 제대로 됨.
WHERE ROWNUM BETWEEN 2 AND 4는 오류는 안 나지만 정상적인 결과가 안 나옴.
순서 부여와 조건 검사가 동시에 진행되서.
ㅁ < WINDOW FUNCTION >
- WHERE절에 작성 불가.
- SELECT절에만 사용 가능.
(1) ROW_NUMBER() OVER (정렬기준)
- ROWNUM처럼 순번을 부여해주는 함수
(2) RANK() OVER (정렬기준)
- 순위를 매기는 함수.
- 동일 순위 이후에 등수를 동일한 인원수만큼 건너 뜀.
(공동 1위 두명 이후 그 다음 순위가 3위)
(3) DENSE_RANK() OVER (정렬기준)
- 순위를 매기는 함수.
- 동일 순위 이후에 등수를 그냥 무조건 1씩 증가시킴.
ㅁ 예제 (급여가 가장 높은 상위 5명 조회)

- 따로 바깥에 ORDER BY 안 써도 윈도우 펑션쓸 때 오더바이 하면 그대로 나옴.
- ROW_NUMBER는 순위 개념은 아니고, 조회되는 순서대로 순번을 부여함.

- ROWNUM과 동일하게 상위 몇명만 조회하고 싶다면 인라인 뷰를 써야 함.
- ROWNUM과 다르게 1부터의 범위가 아니어도 정상 조회됨.
ㅁ 예제 (급여가 가장 높은 상위 5명 조회) (공동 순위면 그만큼 건너 뛰게)
SELECT *
FROM (SELECT EMP_NAME, SALARY, RANK() OVER(ORDER BY SALARY DESC) "순위"
FROM EMPLOYEE)
WHERE 순위 <= 5;
- WHERE의 "순위" 자리에 "ROWNUM"써도 결과는 같다.
3~5 사이 이렇게 줬을 때만 다름.
ㅁ < 상관 서브쿼리 >
- 일반적인 서브쿼리 방식은 서브쿼리의 결과값을 가지고 메인쿼리에서 활용하는 개념.
- 상관 서브쿼리는 반대로 메인쿼리의 값을 가져다가 서브쿼리에서 활용하는 개념.
메인쿼리의 값이 변경되면 서브쿼리의 결과값도 변경됨.
ㅁ 예제 (본인 직급의 평균급여보다 더 많이 받는 사원 이름, 직급코드, 급여 조회)
SELECT EMP_NAME, JOB_CODE, SALARY
FROM EMPLOYEE E
WHERE SALARY >ANY (SELECT AVG(SALARY)
FROM EMPLOYEE
GROUP BY JOB_CODE);
- 이렇게 하면 안 됨.
직급별로 비교가 되는게 아니고, 우연히 직급별 AVG(SALARY)보다 더 큰게 있으면 그것도 다 잡힘.
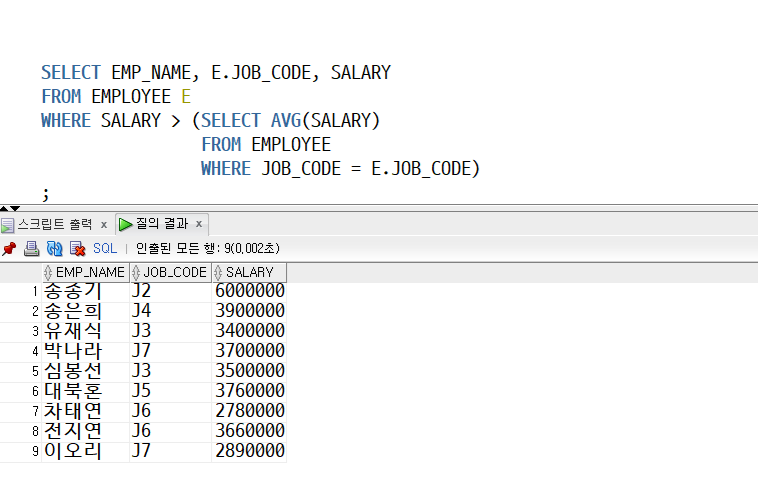
- 메인쿼리의 E.JOB_CODE 값을 서브쿼리에서 활용한다. 그래서 상관 서브쿼리.
- 상관 서브쿼리는 서브쿼리만 드래그해서 실행 불가능 하다.
- E.JOB_CODE 자리는 메인 쿼리의 매행 스캔시마다 매번 달라짐 (서브쿼리의 결과값도 매번 다름)
[서브쿼리를 매행 스캔하는 건 다른 서브쿼리도 그렇지만, E.JOB_CODE 때문에 서브쿼리 자체가 달라짐]
ㅁ 예제 (보너스가 본인 부서의 평균 보너스보다 더 많이 받는 사원의 사원명, 부서코드, 급여, 보너스 조회)

ㅁ 상관서브쿼리면서 SELECT절에 작성된 서브쿼리 (스칼라 서브쿼리)
- 조인하면 서브쿼리 꼭 안써도 됨.
- 정답은 없음. 회사에선 수행속도가 더 빠른 쿼리를 사용.
(그걸 체감하려면 데이터가 몇만건이어야 함)
= 스칼라 서브쿼리는 단일행 서브쿼리다. 꼭 결과값이 한 행만 나와야 한다.
= 뿐만 아니라 열도 하나만 나와야 한다. FROM절과 WHERE절이 같아도 여러번으로 나눠서 써야 함.
ㅁ 예제 (전 사원의 사번, 이름, 직급코드, 직급명 조회)
(1) 조인
SELECT EMP_ID, EMP_NAME, JOB_CODE, JOB_NAME
FROM EMPLOYEE
JOIN JOB USING (JOB_CODE);
(2) 스칼라 서브쿼리
SELECT E.EMP_ID, E.EMP_NAME, E.JOB_CODE, (SELECT JOB_NAME
FROM JOB
WHERE JOB_CODE = E.JOB_CODE) "직급명"
FROM EMPLOYEE E;
- 많이 씀. 프로젝트 할 때도.
- 여기서 E.JOB_CODE를 입력값, JOB_NAME을 출력값이라 함.
입력값(메인쿼리값)과 출력값(서브쿼리값)을 내부 캐시라는 공간에 저장해 둠.
서브쿼리 수행 전에 캐시로부터 먼저 찾아보고 거기에 없으면 서브쿼리를 수행하는 개념.
(J2가 부사장이라는걸 알면, 그 다음에는 J2만 보고 서브쿼리를 수행 안하고 캐시에서 바로 값을 반환) [몰라도 됨]
- 그렇다고 서브쿼리가 항상 좋은 것은 아니고 조인을 쓰는게 좋을 때도 있다.
ㅁ 예제 (전 사원의 사번, 사원명, 부서명)
(1) 조인
SELECT EMP_ID, EMP_NAME, DEPT_TITLE
FROM EMPLOYEE
JOIN DEPARTMENT ON DEPT_CODE=DEPT_ID;
(2) 스칼라 서브쿼리
SELECT EMP_ID, EMP_NAME, (SELECT DEPT_TITLE
FROM DEPARTMENT
WHERE DEPT_CODE=DEPT_ID)
FROM EMPLOYEE;
ㅁ 예제 (전 사원의 사번, 사원명, 사수명 조회) (단, 사수가 없으면 "없음"으로)
(1) 조인
SELECT E1.EMP_ID, E1.EMP_NAME, E2.EMP_NAME
FROM EMPLOYEE E1
JOIN EMPLOYEE E2 ON E1.MANAGER_ID = E2.EMP_ID;
(2) 스칼라 서브쿼리
SELECT E1.EMP_ID, E1.EMP_NAME, NVL((SELECT EMP_NAME
FROM EMPLOYEE
WHERE EMP_ID = E1.MANAGER_ID), '없음') AS "사수명"
FROM EMPLOYEE E1;
ㅁ 예제 (전 사원의 사번, 사원명, 급여, 본인 부서의 부서원 수, 본인 부서의 평균 급여)
(2) 스칼라 서브쿼리
SELECT EMP_ID, EMP_NAME, SALARY, (SELECT COUNT(DEPT_CODE)
FROM EMPLOYEE
WHERE E1.DEPT_CODE = DEPT_CODE) AS "본인부서의부서원수"
, TRUNC((SELECT AVG(SALARY)
FROM EMPLOYEE
WHERE E1.DEPT_CODE = DEPT_CODE)) AS "본인부서의평균급여"
FROM EMPLOYEE E1;
- 스칼라 서브쿼리는 행 뿐만 아니라 열도 1개여야 한다.
FROM절과 WHERE절이 똑같아도 나눠서 써야 한다.
- WHERE에서 어차피 다 걸러서 GROUP BY DEPT_CODE가 없어도 똑같음.
- 집계함수는 GROUP BY 없이도 쓸 수 있음. 결과는 한 행.



'클라우드 활용 자바개발자 양성과정 > 02. 데이터베이스 활용' 카테고리의 다른 글
| 06_DDL(CREATE) (1) | 2024.07.22 |
|---|---|
| 데이터베이스 활용 실습문제 모음 (0) | 2024.07.19 |
| 04. JOIN (조인문) (0) | 2024.07.18 |
| 03. GROUP BY & HAVING (0) | 2024.07.18 |
| 02. SELECT (함수) (0) | 2024.07.17 |


